

ChatGPT as a movie translator
Fiddling around with ChatGPT stories gave me an idea: Would I be able to use ChatGPT as a way to translate movie subtitles automatically from one language to another – specifically from English to Finnish? After a brief search, I found various subtitle formats that I could use for this purpose. I decided to ask ChatGPT which one it recommends.
Which subtitle format would you recommend for a simple test in translating movie subtitles to Finnish?

Alright, SRT it is.
Generating the test material
To get things rolling quickly, I decided to ask ChatGPT to create me some test material:
Generate me a movie subtitle in the SRT -format, with a dialogue of two people discussing the current weather

ChatGPT generated ten lines of dialogue, after which I told it to:
Continue the story, with something exciting happening suddenly
And it kept continuing the story, ten lines at a time. I kept asking it to continue until I had 100 lines of AI-generated movie subtitles. The resulting movie was quite exciting: a story about a man and a woman who spot a child on the basket of a hot-air balloon, rescue them, and witness the beginning of the AI revolution in horror. It unfolds with a nuclear explosion, a frantic retreat to a bunker, and a desperate battle against an invading robot army. It's a typical Hollywood blockbuster condensed into five minutes of relentless action!
I saved the subtitles to a text file for testing. Now I needed to figure out how to translate them into Finnish.
Chopping up
There are a few limitations to the OpenAI API, primarily related to the token count in a message. It's worth noting that the definition of a token may vary depending on the context. Sometimes it corresponds to a word, while in other cases it represents a character. Considering this, it becomes clear that sending the entire SRT file to OpenAI would likely result in an error message.
To work around this limitation, I came up with the idea of creating a Python script that would divide the dialogue into smaller segments and send them individually to OpenAI for translation into Finnish. The translated responses would then be saved to a file. This process would be repeated until the entire file was translated.
As the SRT subtitle format is as follows:
8200:03:48,100 --> 00:03:51,400Each hit, each blow, a testament to their will to survive!
Considering the constraints of token count and cost, it would be optimal to send only the line number and the text to be translated, omitting the timestamp line. This way, we can save valuable tokens and reduce unnecessary expenses. So, we would only need to send the following information for translation:
82Each hit, each blow, a testament to their will to survive!
Using the index number, we could then add the timestamp back to the subtitle file as the answer comes back. So to achieve this, let's ask ChatGPT to create a python script that separates the timestamp from the text:
Create me a python script that takes in an SRT -file as a command line parameter, and creates two new files based on it. The first file will be a list of subtitle indexes, with associated timestamps. Like this:
8800:04:08,500 --> 00:04:12,8008900:04:12,900 --> 00:04:16,200
And the other file will be a list of subtitle indexes with associated subtitle text. Like this:
88In the darkness, they hear a faint hum. It's the generator restarting.
89The lights flicker back on. The bunker is silent, save for the hum.
The ending for the first file will be: _timestamps.tempsrt, and the ending for the second file will be _subtitles_text.srt

I must admit, I could have taken a few extra moments to think of more sensible file endings for those temporary files. However, for the time being, let's stick with the ones we have.
Stitching up
Next we'll ask it to create a method that merges these kinds of files back together, so that once we have translated the subtitle file we can merge it back with the timestamp file:
Now create another python script that takes two command line parameters. The first is a .srt -file, and the next is this _timestamps.tempsrt -file, generated earlier.
The first file looks like this:
'''88In the darkness, they hear a faint hum. It's the generator restarting.
89The lights flicker back on. The bunker is silent, save for the hum.'''
and the second file looks like this:
'''8800:04:08,500 --> 00:04:12,800
8900:04:12,900 --> 00:04:16,200'''
The script then inserts each of those timestamps from the tempsrt-file right after the corresponging index number on the tempsrt -file, so that the end result will look like this:
'''8800:04:08,500 --> 00:04:12,800In the darkness, they hear a faint hum. It's the generator restarting.
8900:04:12,900 --> 00:04:16,200The lights flicker back on. The bunker is silent, save for the hum.'''
The script then saves the file with the given name plus ".appended.srt" ending
And the answer is what we're used to getting:

Doing the translating
Finally we just need to create the script that sends the file without the timestamps to OpenAI API to be translated:
Create me a python file that takes one command line parameter, which is a file with unspecified amount of lines, in the following form, each line representing an index number and one or more corresponding subtitle lines:
88In the darkness, they hear a faint hum. It's the generator restarting.
89The lights flicker back on. The bunker is silent, save for the hum.
The script then sends 40 of these dialogue lines to OpenAI to translate into Finnish, with the following instruction to translate it into Finnish: "Käännä tämä englanninkielinen teksti suomeksi." waits for the response, and then writes that response at the end of a file with the ending _fin.tempsrt

We need to slightly tweak the openai code to make it up-to-date, use gpt-3.5-turbo -model, and increase the token number. The suggestion also does not correctly loop through the entire file, which I'm going to ask it to fix, which is does:
Modify it so that it will loop the lines 40 at a time, all the way to the end of the file.

The translations unexpectedly omitted lines with index numbers, so I made modifications to the sending script. I added a more specific prompt, requesting, "Käännä tämä englanninkielinen teksti suomeksi. Säilytä tyhjät rivit osana vastausta, kuten myös rivit joissa on indeksinumero:\n\n{line}," which translates to "Translate this English-language text into Finnish. Retain empty lines as part of the response, as well as lines with index numbers."
Some of the translated results contained empty lines between the index number and the text. Although I couldn't determine the exact cause, as it wasn't due to anything I had sent, I asked ChatGPT to assist me in creating a cleanup function. This function can be run after receiving the translations to remove those unnecessary empty lines before saving the translations into a file:
Write me a python method that takes string as a parameter, and and removes every empty line that is between a line with only numbers (above) and a line with letters (below), and then return that string
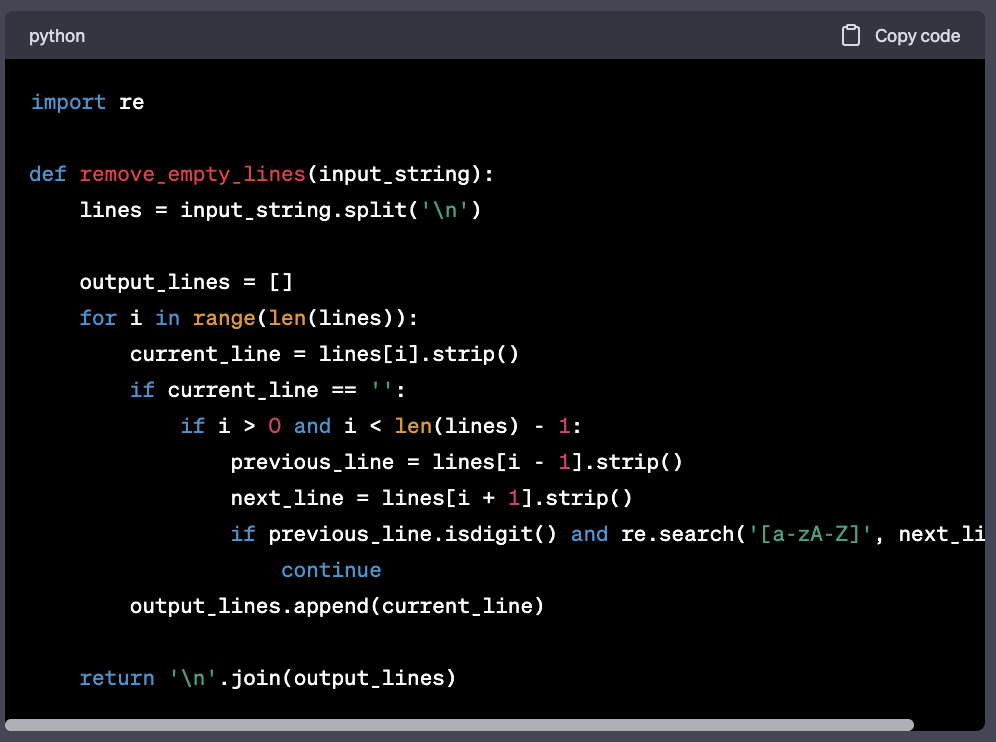
Combining them together
So now I ended up with three separate Python scripts:
1. for chopping the SRT -file to a separate timestamp file and to a separate subtitle file
2. for sending the subtitle file to be translated in chunks and for saving the results
3. for combining the timestamp file to the translated subtitle file
So now I can paste the codes of all of them to ChatGPT, and ask it to create me a Python script that combines their functionality into a single python script.
I have three python files I am running one after the other, and which refer to the same files. Can you merge them so that I have only one python file that does everything they do? Keep the functionality where it creates intermediate files. Here are the three files:
First python script chops the given SRT -file into two separate files:
'''[first script]
'''Second script sends the strings to be translated to openai api:
'''[second script]'''
Third one combines the created timestamp file with the newly translated strings:
'''[third script]'''
And what it returned was exactly what I asked for. However, I don't want to create an overly optimistic impression of how easy this last step was. In reality, it took me quite a while to develop a fully-working script. Its attempts to avoid using intermediate files ended up breaking the code completely. So, I specifically instructed it to continue using the intermediate files.
But once I formatted the prompt correctly and found a way to make it understand my intentions, the resulting code worked flawlessly. I didn't need to make any changes except for inserting my personal API key. Fortunately, at almost that very moment, ChatGPT introduced a feature that allowed me to request the generation of an exceptionally long piece of code. This enabled me to obtain the complete working code without resorting to any further tricks.

But then is occurred to me that the user might want to specify how to translate certain things. For example, translate a name into something specific. Of course making this change was as simple as asking ChatGPT to do that for me:
Modify this script so that is also takes in a third parameter, which is called 'context' and is a string that will be added into the openai message prompt for more context. The parameter is optional and can be omitted:
[full python script]

So, my short project is now ready. I can provide it with an SRT file, along with the necessary context and file-specific instructions, and it will translate it into Finnish. The pricing for using the gpt-3.5-turbo model is $0.002 per one thousand tokens. This token count includes both the prompt and the response. Therefore, when translating text, the cost doubles to $0.004 per thousand tokens to be translated.
Based on the information from ChatGPT, the 100-line subtitle file I used for testing contained approximately 2,000 tokens, resulting in a cost of $0.004 for sending and another $0.004 for receiving the answer. Considering this, if a movie consists of around 3,000 lines of dialogue, the translation cost would be approximately $0.24, and it would take approximately 1.5 hours with the current response time.
My thoughts about all this
The translations, while not comparable to those of professional translators, are still acceptable and sufficient to understand the content. The majority of them are accurate and satisfactory. It is worth noting that the translations can vary considerably each time. Sometimes the translations are overly literal, while at other times they grasp the context perfectly. This variation adds an interesting aspect to the translations generated by ChatGPT:
7
00:00:16,400 --> 00:00:19,000
Aivan. En halua jäädä sateeseen kiinni.
700:00:16,400 --> 00:00:19,000
Aivan niin. En halua joutua sateeseen.
I made some minor adjustments to the code provided by ChatGPT to ensure everything worked perfectly. Other than those tweaks, the entire process was accomplished effortlessly by instructing ChatGPT to write the code for me. It was fascinating to discover that ChatGPT can be utilized to generate test data so easily. I will certainly make use of this capability in the future.
A confession
When putting this approach into practice and translating longer subtitle files, I encountered a challenge inherent in the "organic" nature of AI responses. The AI doesn't always adhere to rules consistently, even when reducing the "temperature" parameter. This resulted in occasional incorrectly formatted responses, albeit infrequently (around one in 30 responses). For instance, it would sometimes mistake the index number for a position and add a period at the end. It could also add or remove extra lines or fail to preserve necessary empty lines.
Since the third part of my script relies on the translated texts being consistently in the correct format, longer subtitle files tended to encounter issues at some point, rendering the combining process unsuccessful. As of now, manual cleanup is required when translating very long scripts to ensure successful combination. It shouldn't be overly difficult to improve the cleanup function to address these issues or enhance the prompt to emphasize the desired format.
However, addressing these challenges is a topic for another time and further exploration.
