

Introduction to Angular compiling
Web application in its core is a big chunk of code that is being stored on a server and parts of it are then moved to a client for a user to be executed. This simple idea already contains challenges: How to make those parts as small as we can so that the user with a poor internet connection does not have to wait too long? What about ease of development process? These are some of the issues that compilers are trying to solve.
Today we will focus on the compiler used by the Angular framework. During its lifespan of two years Angular has seen three different ways of compiling code and every time the process gets a little better.
Angular application is a collection of mostly TypeScript components, modules and HTML templates. The platform where you run your application (usually browser) does not understand these directly and that’s why you need to turn them into a format that the browser can read. First TypeScript compiler turns TypeScript into JavaScript and then that code is given to Angular compiler that turns it further into an efficient JavaScript that can then be given to the platform.
If we shortly look into what Angular compiler actually does, it takes our templates, directives and bindings. The parser in Angular compiler then creates an Abstract Syntax Tree, or AST, out of elements and bindings and turns our directives into a map. It also checks that everything in the syntax is correct. After this the compiler takes the AST and turns it into instructions on how to create Document Object Model a.k.a. DOM elements. Compiler will also take care of making our nice error messages with line numbers and handle change detection for our bindings. Next step is to combine everything together into view, an instance of a template. JS compiler in browser then knows how to read the view and create the web page element that user actually interacts with.
In case you’re interested in really going deep into this process I recommend checking out this talk by Tobias Bosch in Angular Connect 2016.
In the days of AngularJS, parsing HTML and creating DOM was done by browsers. This method came with a couple of issues. First was that errors were difficult to locate. After the DOM tree was generated from HTML templates the end result could be different depending on the browser you were using. This would make locating errors very difficult, if you ran into problems you could no longer find the broken part.
Second big issue was inconsistency between browsers. Things like case sensitivity differ from browser to browser, so you might have to create multiple different versions if you want to make sure you are supporting a large array of platforms.
In the beginning there was Renderer
The first Angular compiler was called Renderer. If we want to get deeper into the topic we should note that Renderer is actually a service providing an abstraction layer for the Angular compiler. This text will however use terms Renderer and compiler interchangeably for the sake of simplicity.
Renderer used Just in Time (JiT) compiling by default. JiT compiling means that code is compiled during runtime. The package sizes were still large, partially because the compiler had to be moved to browser. Compiling with Renderer was still an improvement to AngularJS compiling because developers no longer had to worry about consistency between different platforms and it was possible to locate errors. Browsers won’t let the developer know about line numbers for the piece of code that is causing an error and they will also try to solve problems on their own, obscuring them even further in the process.
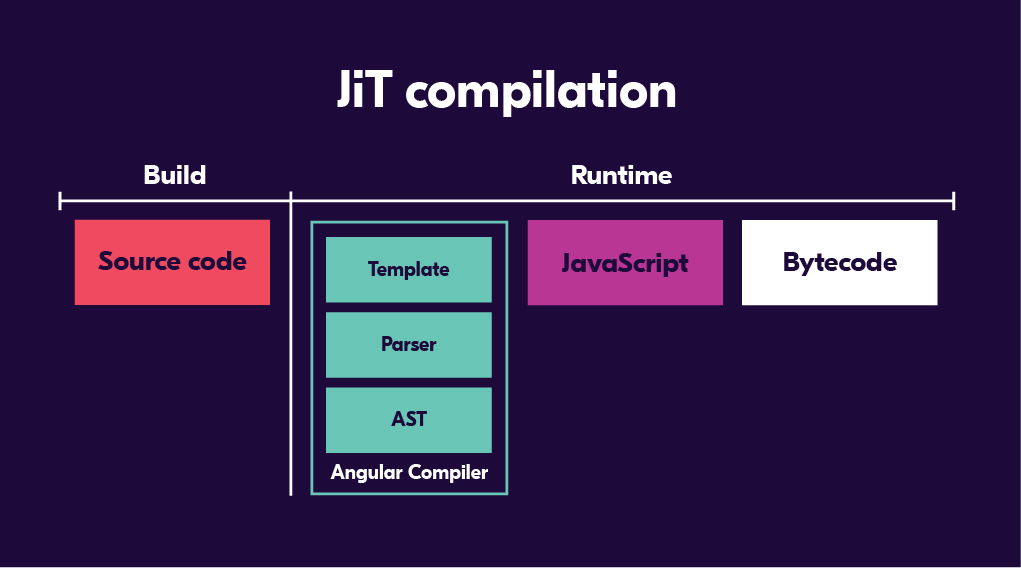
Angular 4 and Renderer 2
With Angular 4, the next iteration of Renderer, a.k.a. Renderer 2, was released. Google called this release “an invisible makeover” that on the surface didn’t change much. However, under the hood Renderer 2 brought us Ahead of Time (AoT) compiling. AoT compiling means that we first compile the code given to us by the TypeScript compiler before loading it to browser. That way we can eliminate things like Angular compiler from the final package. So with this approach we should at least in theory end up with a smaller package size. The truth is a bit more complicated but it was a step in the right direction. This was also the point in time when view engine was coined as a term. This is why Renderer 2 and Ivy are sometimes referred to as view engine but Renderer is not.
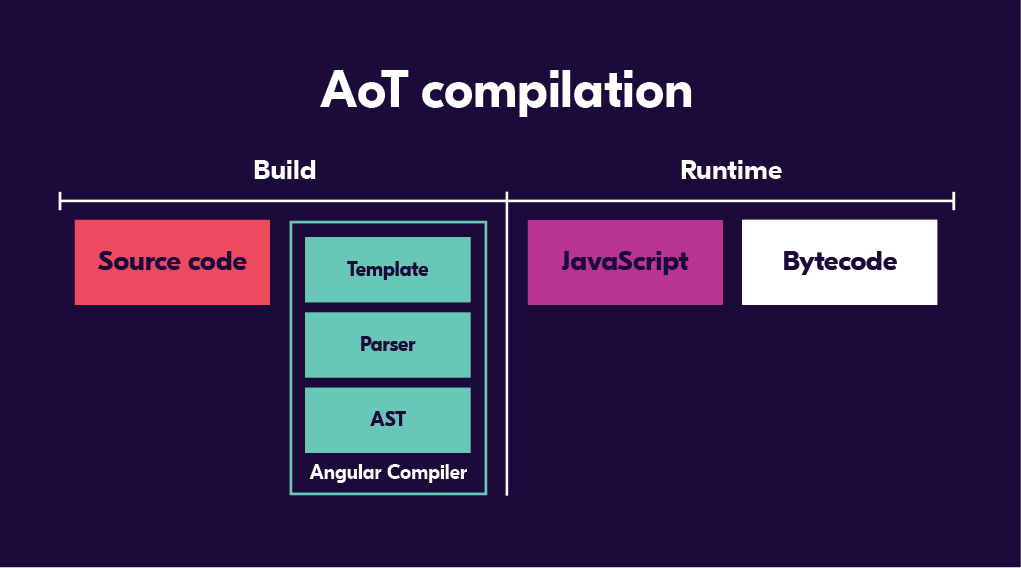
Sprouting Ivy
Renderer 2 was an improvement from the previous version but there are still issues to solve. The upcoming view engine and rendering pipeline for Angular is called Ivy. Rumor has it that it will be released with Angular 8 in April 2019.
By using locality Ivy will make change detection more efficient. During compiling Ivy handles a single file at a time without having to care about dependencies to other files. End result will be small atomic functions that are easy to check for changes and to tree-shake. In previous Renderers during change detection everything had to be checked every time something changed in the DOM. With Ivy change detection runs only on a small portion of the code.
Previously mentioned atomic functions are easier to tree-shake because it’s easier to detect if something is being used or not. By trimming unnecessary pieces you reduce the final package size. Previous iteration of view engine would sometimes give “false positives” when tree-shaking and keep code that was actually never run.

Code that previous tree-shaking would not catch. Sadfunction will never be executed, but will still be included in the bundle.
Another great improvement with Ivy is that the compiled code will be more human readable. When comparing code compiled by Renderer 2 and Ivy the latter is easier to understand if you need to dig deep in your code.
In conclusion
This was a very brief introduction to the history of Angular compiling. After the rise of mobile applications that application like feel also got high demand in web development. Loading times are, now more than ever, poison to any user. Efficient compiling plays a big role in reducing loading times and making that positive user experience happen. Having to consider things like JiT and AoT compiling in development process might not look like they’re making things easier for developers at first glance, but in the long run things like tree-shaking will also give developers more breathing room. The goal is always to write code that has as little amount of bloat as possible, but if I miss something and leave an unnecessary module hanging around by accident, I don’t mind the compiler giving me a hand and cutting that off automatically. Release of Ivy will quite possibly be one of the turning points for Angular as a framework. Personally I’m not a proper fangirl of any JavaScript framework or library but it will be interesting to see if this improvement will raise the popularity of Angular in a larger scale.
Sources:
A deep deep deep deep deep dive into the Angular compiled by Uri Shaked
